Before learning about this concept, I used to believe that the best data scientists to date might be using some techniques, algorithms, or any kind of labs that lead them to better prediction. But when I started learning the things, I perceived that these guys are not using any rocket science kind of things.
So I realized that whatever techniques or concepts you use, without Feature Selection you won’t make the right choices for your prediction. Wrong choices leads to lots of garbage i.e. noise.
This topic is bit vast, I will not put all the sub-topics like its methods and techniques in detail in just one article. Here, I will just introduce you what is this concept with examples.
Classification of Feature Selection
Basically there are 2 types of features selection-
1. Manually selecting features = Here the role of domain expert comes into play. In case of big data, its very hard to predict using manual method.
2. Feature selection using Algorithm = There are many types of methods here-
1. Filter Method.
2. Wrapper Method (widely used by Deep Learning)
3. Embedded Method ( Lasso Method)
Selecting the best features is a pivotal step in Machine Learning. It is the process of selecting features which leads us to the prediction variable or output. Choosing wrong or irrelevant features may lead to less accuracy of the models. This concept is also known as Variable Selection. It mainly focus on removing those features which does not provide any information or are unnecessary ( have no effect) on the prediction of model.
Feature Selection enables Machine Learning models to train faster and reduces the difficulties and makes easier to explain by reducing overfitting.
Filter Method
It is a preprocessing step. Features are selected on the basis of correlation function which helps to filter the correlating data. It is an estimate of the linear connection uniting 2 quantitative variables. It ranges from -1 to 1, more the unit of this number increase, your output value will decrease.
Correlation is a good way but it doesn’t give 100% appropriate answer because it is embedded inside the model. In case of Big Data, this method might take 1 or 2 days to create model.
Embedded Method
In Embedded Method, they perform feature selection during the model training. We have one more method i.e. Lasso Method, where we create the model and train it and use the coefficient to find the output. Coefficient gives the accurate answer as we use it after we train the model.
Eg- When you’ve to launch a web server and you have no idea about how much computing space like RAM, CPU, Hard disk, buffer size, buffer memory to allocate, company gives some generic guidelines which needs a customised model. Lasso method is useful in such cases, as it helps us in telling which feature is important and how much space to allocate for each feature.
If your requirement is to do a feature selection to remove features and if you are using embedded method, there are two types of this method-
1. Lasso Method.
2. Ridge Method
Lasso Method
Lasso method is also known as L1 method or L1 regularization, it uses embedded method to for faster and better way of feature selection. After training the model, Lasso or L1 method is a better way for feature selection.
Lets understand with an example of Feature Selection by Embedded Method using Lasso Method, you can also refer the code, but this code is not enough for feature selection as there are many more things to do. I’ve just shown you the overview of how Lasso method works-
The dataset I used here is a ideal use-case, in real-life, we don’t have such kind of exact datasets. Our target is to get the output i.e. ‘y’. corr( ) function is used to correlate the data. Threshold function is used to find whether any column have constant variable. NaN denotes that the correlation is zero.

Next, we will create a model. Linear Regression is an estimator or algorithm. Model.fit( ) function finds the value of weight. Coeff( ) function is used for getting value of coefficient. Here, we will create a model. Linear Regression is an estimator or algorithm. Model.fit( ) function finds the value of weight. Coeff( ) function is used for getting value of coefficient. This makes a formula-
y = b + cx
y is our column which we’ll use for predicting, b is bias. In my next article, I will explain this concept in detail.

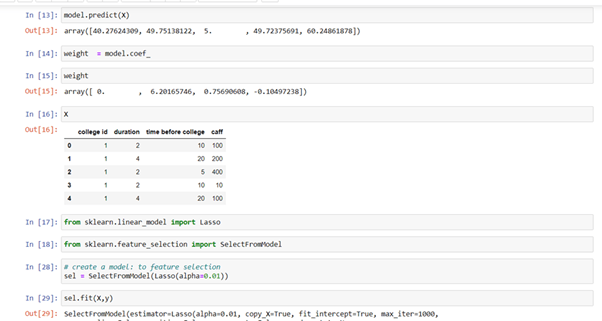
Here, I’ve imported lasso module. SelectFromModel( ) function helps us to select features from Lasso model. Alpha value is to be given for hit and trial method. I gave 0.01 as a alpha value because I’ve short dataset, you can give any value depending on how big your dataset is. After fitting the data, get_support( ) function tells us the status of each column where false denotes how useful the column is, True denotes how useful the column is. Estimator_.coef( ) function gives the coefficient of the column. The values show how important the features of a particular columns are.

This was a brief overview of how Lasso method helps us for feature selection. There are many more concept, techniques and algorithms in feature selection which I’ll include in my next article.
Thanks for reading.

One thought on “Feature Selection in Machine Learning – Introduction”